Adopt Good Cyber Security Practices to Make AI Your Friends not Foes
Artificial intelligence (AI) has experienced a rapid growth in its adoption by businesses in recent years. According to the International Data Corporation, companies around the world plan to increase their spending on AI solutions (e.g. hardware, software, services, etc.) by 19.6% in 2022 to US$ 432.8 billion, and to exceed US$ 500 billion in 2023 [1]. As the application of AI becomes more diverse, greater attention must be attached to its associated security risks. Otherwise, it may end up doing more harm than benefits.

What is Artificial Intelligence?
AI is the simulation of human intelligence by machines. These “human intelligence” can include learning, problem-solving and pattern recognition etc. AI is currently undergoing a phase of vigorous development, such as the improvement of computing power, robotics and statistics, as well as the increasing volume of data.
The application of AI is becoming more diverse: from its better-known applications like computer vision (e.g. pattern recognition, facial recognition) and natural language processing (e.g. machine translation, voice recognition), mimicking human cognitive behaviours such as cancer detection, to even analysis of legal cases and creative processes like poetry writing and art making. In the field of cyber security, AI can even be used to detect and identify malware [2].
Artificial Intelligence and Machine Learning
The term machine learning (ML) is often mentioned alongside AI but they are not synonymous. ML can be seen as a branch of AI, more specifically, the use of mathematical and statistical methods to gain insights from data, to predict the future outcomes and solve problems based on the developed model. This is similar to the human experience of “learning”, hence the term “machine learning”.
Machine Learning versus Traditional Programming
One could think of programming as the designing of “rules” to process inputs and produce outputs. What ML does is by gaining insights from sufficient known inputs and outputs, and then generates the “rules” to process future inputs and execute commands to produce sufficiently accurate outputs automatically [3].
Supervised Learning
There are plenty of approaches to ML, with the most common one called Supervised Learning [4].
Fundamentals of Supervised Learning
In supervised learning, a dataset is collected to train a mathematical model, where the dataset includes data of one or more inputs (or called features) and outputs (or called labels). By feeding this data into a model, it completes the algorithm to spit out outputs according to calculations with its parameters.
Figure 1: A Basic Scheme of a ML model with Images of Apples and Strawberries being the Features and the Word Associated with them (’apple’ or ’strawberry’) the Label.
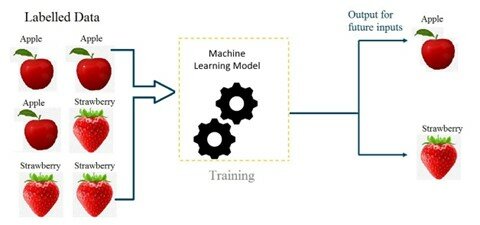
Source: https://ai.plainenglish.io/introduction-to-machine-learning-2316e048ade3 [5]
Optimisation Techniques - Gradient Descent
At first, the model does not know how to predict outputs apart from random guessing. The model gradually ‘learns’ to predict better through the optimisation technique of gradient descent.
By comparing the difference between predicted outputs and their actual outputs, we could define a loss function that represents the performance of the model. A low loss function denotes that the predicted value is similar to the actual value. This loss function depends on the parameters in the model. Though updating these parameters, we can find an optimal values of parameters to achieve a minimum value for the loss function [6].
Security Risks of AI-powered Services
Compared with the traditional systems, AI-powered services carry greater and broader potential security risks.
For a start, as mentioned above, AI is powered by a large volume of data and computation. If these training data consist of sensitive personal information, leakage of training data can result in sensitive information disclosure [7].
Also, as the collection of training data can come from various sources, AI-powered services are susceptible to the risk of cross-leakage. For example, if one was to train a disease detection model, biological information of patients would have to be analysed. When the patient data is collected from one hospital, it is paramount to ensure such information cannot be accessed by other hospitals.
Moreover, if AI-powered services are being attacked, their adverse effects can be more serious than traditional ones. This is because multiple services might use the same machine learning model. If the model is being attacked, all services powered by that model will be affected as well.
No matter we are the users of AI or not, the cyber security of AI affect everyone. Let us discuss how these risks can affect different stakeholders in two aspects: “Security Loopholes” and “Malicious Uses and Abuses”.
Security Loopholes
Membership Inference Attack
The inferencing of training data through reverse engineering on the machine learning model (i.e. “target model”)[8][9]. This way of attack is based on the fact that the training model performs differently on seen and unseen data[10]. One indicator is the difference in the confidence level it gives. By observing the behaviour of the output, we may be able to infer if a certain input data is a part of the training dataset.
The method is to train a shadow model that mimics the target model’s behaviour by deploying the same model structure and training it with data similar to the original training data. They behave similarly to the target model in the sense that they respond to seen inputs similarly. Finally, an attack model can be trained by ensemble learning on the shadow models to take the behaviours of the target model as input and whether the data in question is in the training dataset or not as an output.
A visualisation (Figure 2) by Cornell University illustrated the above mentioned attack model.
Figure 2: An Attack Model formed through Ensemble Learning with Shadow Models
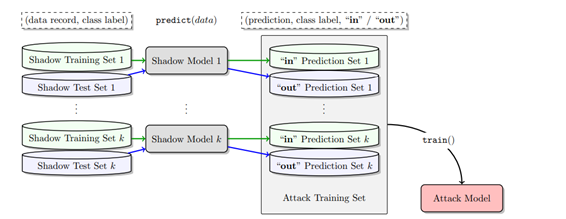
Source: https://arxiv.org/pdf/1610.05820.pdf[10]
Membership inference attacks mainly affect tabular data. In a research by Cornell University, by using this method of attack, 60% of data in the outpatient record of a hospital in Texas could be inferred. This record includes sensitive information like diagnosis, type of treatment, and type of injury.
Adversarial Perturbation
It refers to provision of perturbed versions of inputs to the machine learning model to fool it. This type of attack is based on slight alteration of training data in order to decrease the accuracy of the model. There are two types:
Evasion Attacks (one-off impact)
It directs the model to misclassify a certain target class of data to get desired labels of the attacker by introducing meaningless inputs (i.e. noise) [11]. This kind of input tampering could be unnoticeable but remains greatly effective in fooling the learning model.
A conference paper from Google demonstrated the concept and potential result below: The panda has been added with suitable noise and the model misclassified it as a gibbon.
Figure 3: Demonstration of an Evasion Attack


Source: https://arxiv.org/pdf/1412.6572.pdf[12]
Poisoning Attacks (substantial impact)
It introduces misleading training data to make the model misclassify. The attacker compromises the AI model in the learning stage and inject manipulated data into it [13]. The aim is to corrupt the model and produce the output desired by the attacker in the future. It has a serious impact as it can affect the model substantially if not discovered.
In 2017, the spam email classifier in Gmail was attacked, and attackers mass reported spam emails as not spam so that these actions will be fed into the filtering model as data for retraining. It aims to make the model unable to filter out some spam or malicious emails, so that attackers may then send phishing emails while avoiding the filter [14].
Also, in 2016, Microsoft launched Tay.ai, the AI chatbot that learns from conversations with users and improves itself. Some users sent large amounts of hateful and racist comments to Tay.ai to contaminate its training data, resulting in Tay.ai also adapting to speak with these hateful remarks. The chatbot was shut down only 16 hours after its initial launch [15].
An experiment conducted by researchers in Bosch AI demonstrated that it is possible to insert adversarial perturbations into street views so that the image segmentation model cannot detect pedestrians (Figure 4) [16]. If autopilot systems are being attacked this way, the car may crash into pedestrians and cause great casualties.
Figure 4: Original Image Segmentation (top right)
vs Image Segmentation after the Input is Perturbed (bottom right)

Source: https://www.bosch-ai.com/research/research-applications/universal-adversarial-perturbations/[16]
Another malicious application of this attack is to take advantage of the retraining mechanism used in the machine learning models which use customer feedback as input. For example, some online shopping recommendation algorithms may use the browsing behaviour of customers as data for retraining. Attackers can affect the model to obtain their desired result.
Malicious Uses and Abuses
Deepfake
It refers to the use of Deep Learning technology to create fake video/audio. This technology is most known in its video form, where the face in the video is swapped with another person’s likeness. However, Deepfake could also be used to synthesize human voice in imitation of a particular person, and the realistic voice of the victim could be synthesized just by inputting a text script.
Currently, Deepfakes can even lip-sync the victim with an audio clip provided[17], meaning one video clip instead of two might be enough to make Deepfakes. Deepfake uses machine learning algorithms like the Autoencoder and the Generative Adversarial Network.
Nowadays, making Deepfakes are increasingly easy using open-source software on GitHub that produces Deepfakes. While Deepfakes can be entertaining when it is used to make movies and Internet memes, the technology can also be used maliciously, like the production of pornography, spreading of rumours or even circumventing biometric authentications.
For example, in the 2022 Russian Invasion of Ukraine, the likeness of both presidents of Ukraine and Russia have been abused to produce Deepfake videos to spread rumours.
Video 1: A Deepfake of Volodymyr Zelensky, President of Ukraine
Source: https://www.youtube.com/watch?v=X17yrEV5sl4[18]
Video 2: A Deepfake of Vladimir Putin, President of Russia
Президент РФ обьявил о капитуляции россии. Русский солдат, бросай оружие и иди домой, пока жив! pic.twitter.com/5wWC3UlpYr
— Serhii Sternenko (@sternenko) March 16, 2022
Recently, the Federal Bureau of Investigation of the United States reported a case of attackers gaining access to customer and financial information of tech companies through impersonating job seekers and interviewing for remote job positions [20].
State-of-the-art deepfake detection technologies cannot fully detect deepfakes. In 2020, Microsoft and Facebook (now Meta) jointly held a deepfake detection competition, with first place achieving an accuracy of only 65.18% [21].
However, it is worth noting that victim photos must be abundant for the deepfake to have sufficient training data. Therefore the victims of deepfake are usually public figures, with their photos readily available in large volumes over the Internet.
Security Advice
To mitigate these security risks, technical solutions include the validation of training data, the usage of anti-fake technologies and the prevention of overfitting. However, some existing cyber security measures may also help avoid these risks: the protection of data is paramount in the development of artificial intelligence. There are still measures to take to protect yourself even if you are not tech-savvy. Enrich the understanding of these technologies and always fact check any information from Internet.
Select Appropriate Models to Prevent Membership Inference Attacks
Membership Inference Attacks arise from the fact that there is a noticeable discrepancy between the output of a seen input and that of an unseen input. If a training model adheres to its training data too much, it may perform poorly on new unseen data despite performing well on training data. This is called “Overfitting” in statistics. An overfitted model behaves noticeably different on seen and unseen data, helping attackers to infer membership of a certain data [22].
Overfitting can be caused by excessive parameters in the training model, data being too noisy or insufficient. To avoid overfitting, a suitable architecture for the model has to be selected. Do not measure the performance of a model solely on its accuracy on seen data. Some model validation methods such as the k-fold cross validation can generate an accuracy value that closely approximates the model’s ability to generalize to a new and independent dataset. When training the model, we have to make sure the training data is sufficient and being cleaned. Make sure to check if the loss increases periodically as time goes on and stop the model early if needed.
Validate Training Data Before Updating the Model to Prevent Adversarial Perturbations
Many AI-enabled services utilize user feedback as retraining data, meaning the actions of users can affect the future behaviour of the model. Some attackers might take advantage of this fact and perturb the model adversely. Therefore, validation of new data is needed before the model is fed with the data for retraining. Limitations on individual contribution to the retraining dataset could also be imposed to avoid a small group of users steering the model [23].
Improve Privileged Access Management (PAM) Policies
Apply appropriate access control of customers and employees to sensitive information, therefore preventing the data from being tampered unauthorisedly.
Use Anti-Fake Tool to Protect from Deepfake
Currently, there are many anti-fake tools we may use to detect deepfake videos. We may add digital watermark on our personal photos and videos. If these photos and videos are taken to synthesize deepfakes, the digital watermark will be changed, so that the deepfake video can be detected. Although deepfakes can be realistic, most deepfakes available on the internet are amateurish and may be detectable with bare eyes. Cyber security company Kaspersky provided six characteristics of deepfake videos as below [24]:
- Jerky movement
- Shifts in lighting from one frame to the next
- Shifts in skin tone
- Strange blinking or no blinking at all
- Lips poorly synched with speech
- Digital artifacts in the image
You may now watch the deepfake video above again and see if you can tell the difference. (Note: These characteristics only apply to amateurish and low quality deepfakes at this moment. As deepfake technology evolve, one may not tell a deepfake from a real video just with bare eyes.)
Enhance understanding on deepfakes
Apart from leveraging technology to detect and curb deepfakes, we can also raise our awareness and knowledge of deepfakes. Media literacy is also important in minimizing the adverse effects of deepfakes: when watching the news, use credible sources, always verify and do not trust blindly.
Conclusion
As AI becomes increasingly powerful and ubiquitous, the weaponisation of AI becomes more and more viable. Whether you are a user of AI or not, you may still be a victim of these attacks. Therefore, an understanding of the potential dangers of AI helps us stay vigilant, so that we may enjoy the benefits brought forth by AI, not in the expense of its security dangers.
References
[1] https://www.idc.com/getdoc.jsp?containerId=prUS48881422
[2] https://techbeacon.com/security/how-ai-will-help-fight-against-malware
[3] https://machinelearningmastery.com/basic-concepts-in-machine-learning/
[4] https://www.youtube.com/watch?v=Ye018rCVvOo
[5] https://ai.plainenglish.io/introduction-to-machine-learning-2316e048ade3
[6] https://machinelearningmastery.com/gradient-descent-for-machine-learning/
[7] https://hubsecurity.com/blog/cyber-security/security-threats-for-ai-and-machine-learning/
[8] https://bdtechtalks.com/2021/04/23/machine-learning-membership-inference-attacks/
[9] https://www.youtube.com/watch?v=rDm1n2gceJY
[10] https://arxiv.org/pdf/1610.05820.pdf
[12] https://arxiv.org/pdf/1412.6572.pdf
[13] https://towardsdatascience.com/poisoning-attacks-on-machine-learning-1ff247c254db
[14] https://elie.net/blog/ai/attacks-against-machine-learning-an-overview/
[16] https://www.bosch-ai.com/research/research-applications/universal-adversarial-perturbations/
[17] https://bhaasha.iiit.ac.in/lipsync/
[18] https://www.youtube.com/watch?v=X17yrEV5sl4
[21] https://pansci.asia/archives/342421
[22] https://elitedatascience.com/overfitting-in-machine-learning
[24] https://www.kaspersky.com/resource-center/threats/protect-yourself-from-deep-fake
Related Tags
Share with